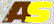


Bayesovské Adaptivní Distribuované Dynamické Rozhodování
![]()
![]()
![]()
|
|
|
Bayesovské Adaptivní Distribuované Dynamické Rozhodování |
|
Poslední aktualizace: 28.1.2008 © Thritton |
 |
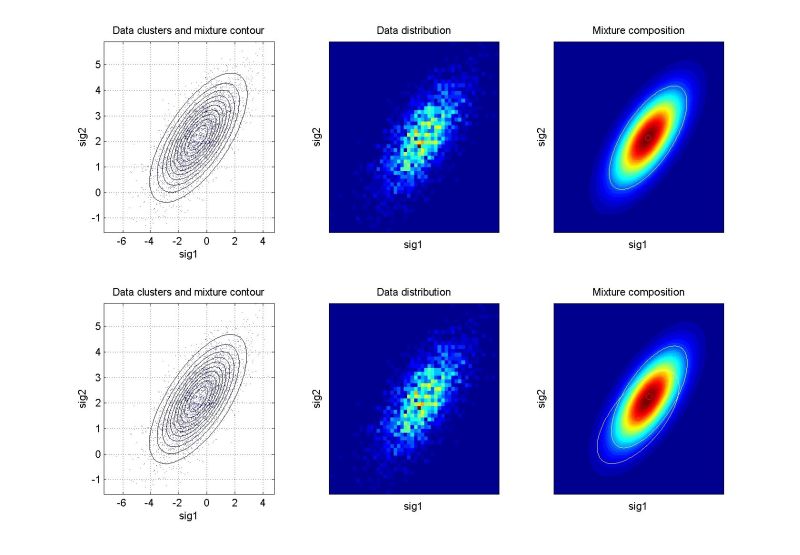
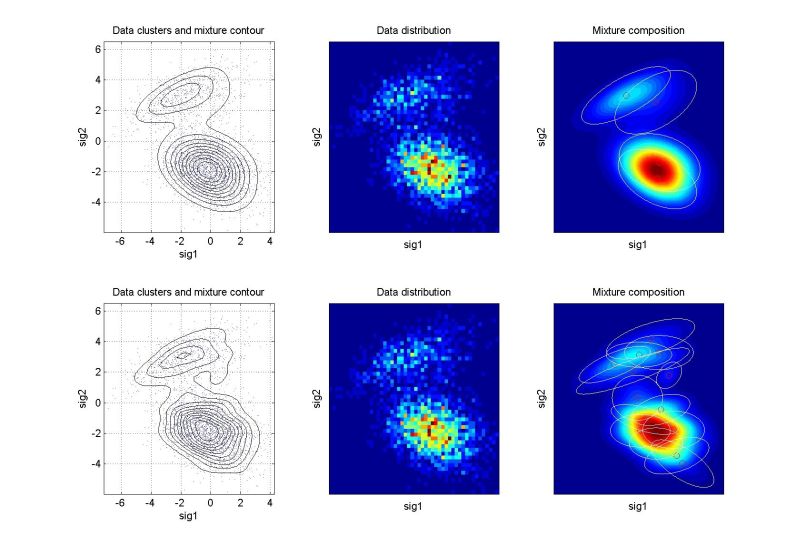
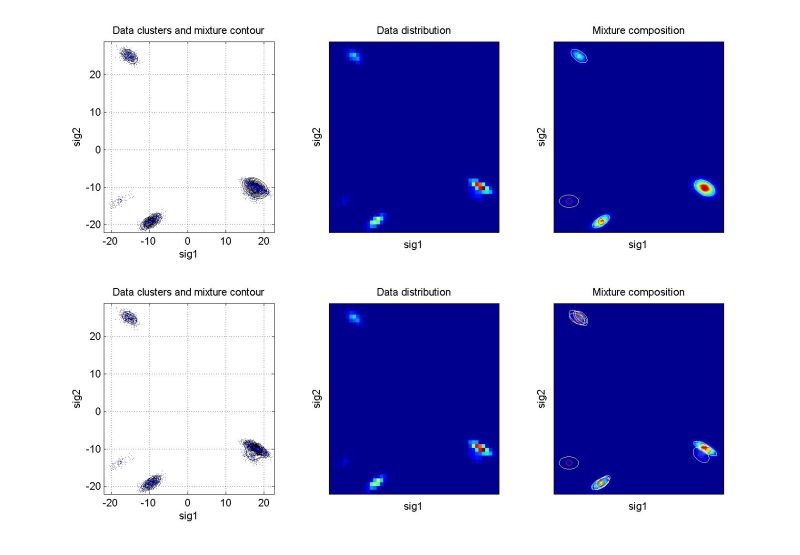
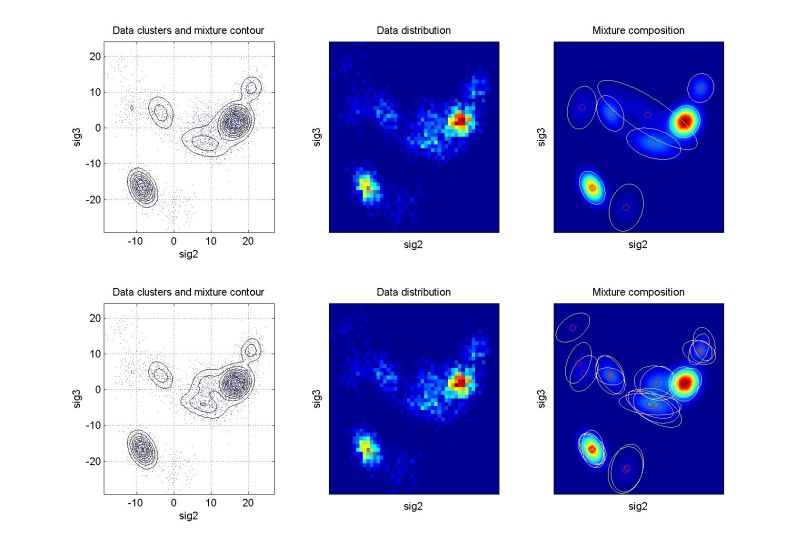
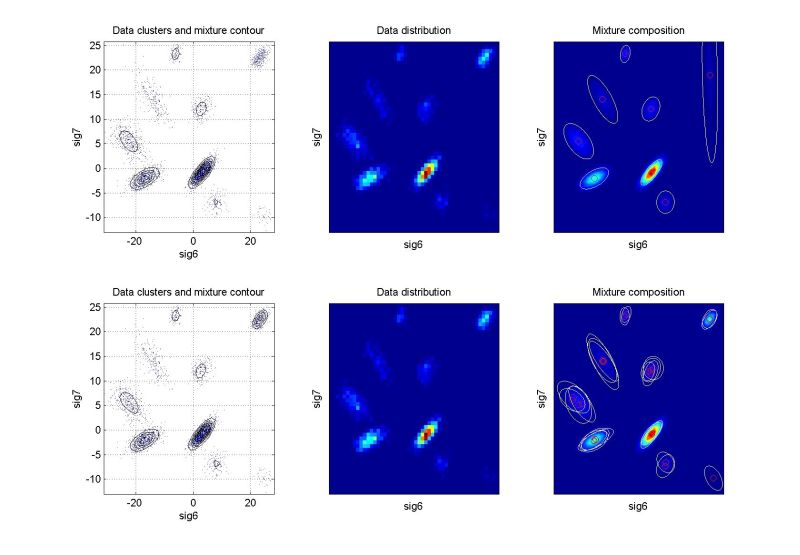
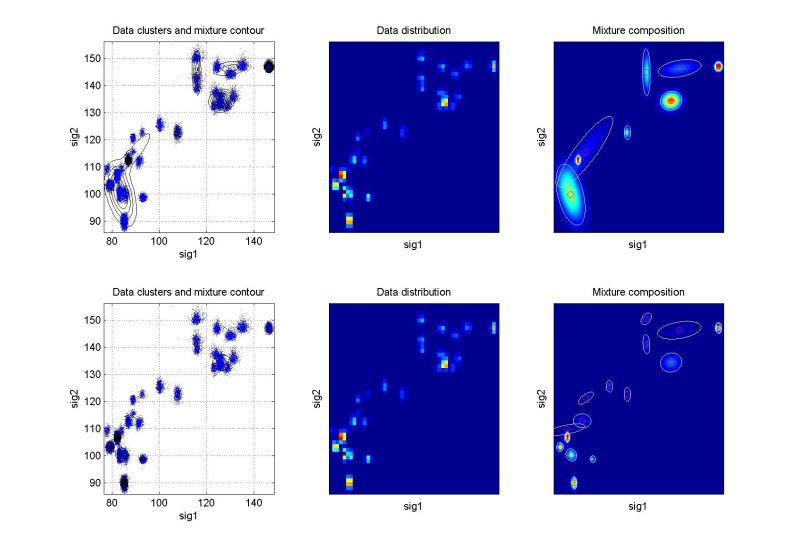
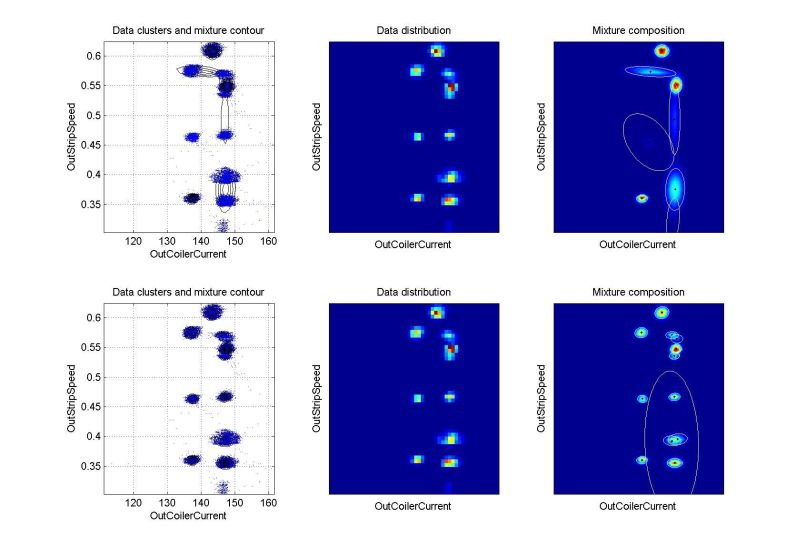
Odhadování pravděpodobnostních směsíŘádky grafů odpovídají prvnímu, resp. druhému cyklu identifikace. Levý graf znázorňuje rozložení dat a konturu výsledné pravděpodobnostní směsi. Prostřední graf ukazuje dvourozměrný histogram relativní četnosti dat – tzv. empirické rozložení pravděpodobnosti, jemuž by se měla pro statický případ odhadnutá směs blížit. Pravý graf ukazuje kompozici směsi. Pro vícerozměrné případy je uvedena pouze vybraná dvourozměrná projekce. Další kritéria pro hodnocení kvality identifikace jsou založena na vyčíslení věrohodnosti odhadu a v případě dynamických směsí na posouzení chyby predikce. Podrobnějsí informace budou postupně k dispozici na stránce odkazy a články. Význam proměnných v následující tabulce: ndat – počet datových vzorků, ndim – počet datových kanálů (dimenze), ncom – počet komponent v simulační směsi. U vícerozměrných směsí (ndim > 2) je navíc uvedeno, které dimenze jsou v projekci použity. Kliknutím na grafy se zobrazí zvětšený obrázek. Simulovaná data – statické směsiExperimenty nad simulovanými daty mají zřejmou výhodu, že je známo “co má vyjít”. Slouží pro ověření funkčnosti algoritmů.
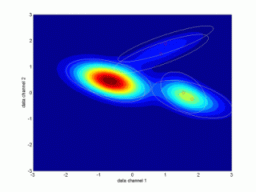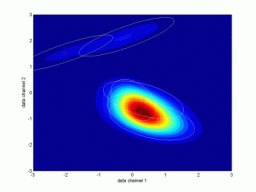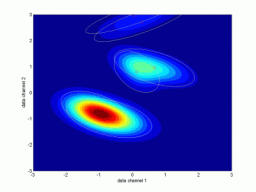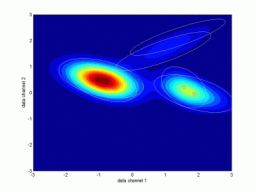
Simulovaná data – dynamické směsiU dynamické pravděpodobnostní směsi hraje úlohu posloupnost datových vzorků. Proto při jejich grafickém znázornění je třeba zadat jako parametr čas, resp. definovat konkrétní datový vzorek, jehož se zobrazení týká. Směs slouží ke generování predikce dat na jeden nebo více kroků dopředu. Následující obrázek ukazuje příklad dynamické směsi, která byla identifikována ze simulovaných dat s dynamikou 1. řádu. Aktuální datový vzorek neodpovídá původním datům, ale pohybuje se v rovině po kružnici.
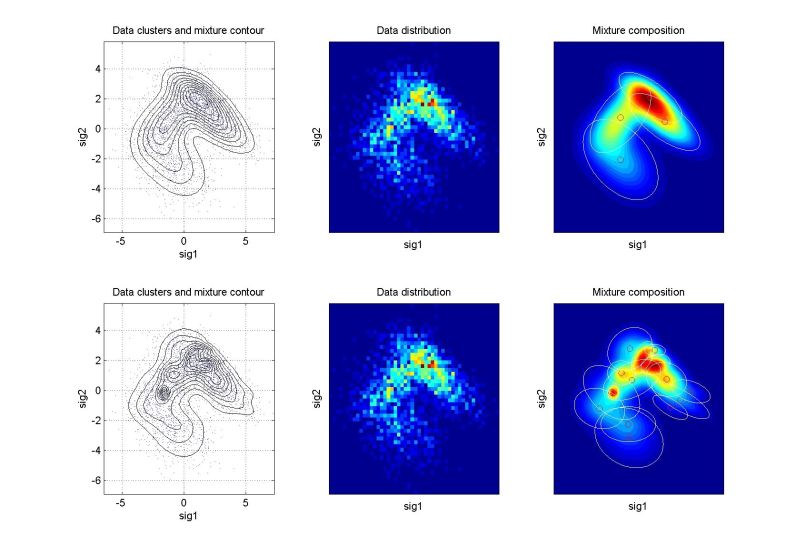
Reálná data
|
||||||||||||||||||||||||||||||||||||||